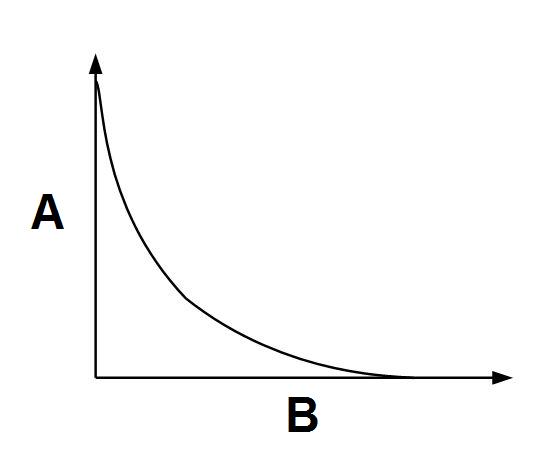
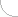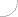Les données originales représentant des images et des séquences vidéo enregistrées au format RGB contiennent des informations excessives et négligeables. Les premières peuvent être reconstruites à base d'autres données relatives à la même image. Par contre, les informations négligeables ce sont des informations dont la suppression n’entraîne pas la détérioration remarquable de la qualité de l'image. La structure des algorithmes de compression permet d’évaluer automatiquement quelles informations jugées négligeables provoquent des déformations les moins visibles pour un observateur. Le degré de compression obtenu dépend dans une grande mesure du contenu de l'image, ainsi que de la réduction acceptable de la qualité de l’image. Le graphique ci-dessous (fig. 1) présente le rapport théorique entre le flux de données et la déformation.
Fig. 1. Déformation de l'image en fonction du volume du flux de données
A Flux de données B Déformation
Nous distinguons la compression à l’intérieur de l’image et la compression inter-images. Dans le premier cas, il faut chiffrer l’image entière, indépendamment des autres cadres de la séquence. Dans l’autre cas, le chiffrage dépend des cadres précédents et suivants.
Représentation des couleurs
En règle générale, les images en couleur sont compressés. En ce qui concerne les écrans, les images y sont obtenues par suite du mélange de trois couleurs de base: rouge, verte et bleue (RGB). Chaque pixel est représenté par la somme de ces trois composants. Malheureusement, la taille des données ainsi enregistrées est énorme. En raison de la nature d'un oeil humain, il est préférable d’enregistrer les données sous la forme de luminance Y et de deux chrominances différentielles Cr et Cb, où:
Un avantage est que l'oeil humain est le plus sensible au changement de clarté des points représentés par la luminance et il est moins sensible au changement de couleur représentée par la chrominance. Par conséquent, il est possible de soumettre le signal de chrominance à la décimation. Une telle propriété a déjà été utilisées dans les systèmes de télévision analogique, tels que PAL, SECAM ou NTSC, en destinant une bande deux fois moindre pour transmettre le signal de chrominance sans réduire la qualité de l’image de manière remarquable
Compression à l'intérieur de l'image
Le principe des techniques contemporaines de compression est le fait que le spectre du signal vidéo est très concentré autour des fréquences les plus basses. Par conséquent, il suffit de calculer le spectre du signal et enregistrer seulement quelques coefficients ayant un impact significatif (généralement ceux aux basses fréquences) et les autres (d’habitude ceux qui correspondent à des fréquences plus élevées) peuvent être enregistrés sur un très petit nombre de bits.
En pratique, on divise les images en blocs de 8x8 points et on calcule la transformée en cosinus (transformée de Fourier modifiée). La suite obtenue est divisée par une table de quantification spécifique. Par suite de cette opération, on obtient beaucoup de zéros qui se répètent. La représentation obtenue est enregistrée dans les paires suivantes: nombre de zéros, la valeur d'un coefficient de non-zéro. Les résultats obtenus sont enregistrés au moyen de codes dont la longueur des bits est variable. Cela signifie qu’on attribue des codes avec un nombre inférieur de bits aux paires plus fréquentes, tandis que les codes avec un plus grand nombre de bits sont attribués aux paires qui sont plus rares.
Compression inter-images
Le principe du chiffrage inter-images consiste à profiter du fait que les cadres suivant et précédent dans une séquence vidéo sont généralement similaires. Par conséquent, il suffit d’envoyer une erreur de prédiction, donc la différence entre l'image et sa prédiction. Dans le cas le plus simple, il est prévu que l'image suivante est identique à celle précédente.
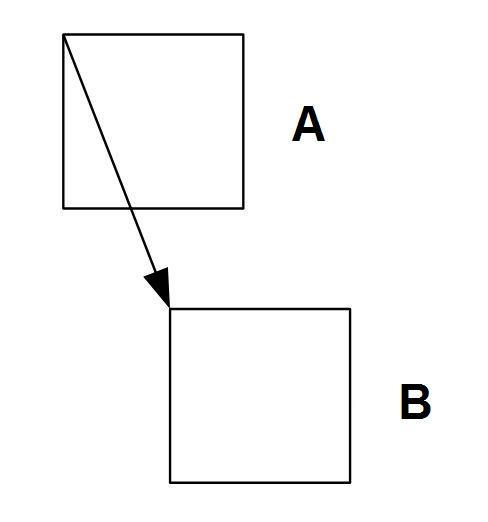
Dans les codeurs les plus avancés, la compensation de mouvement est utilisée pour la prédiction. Pour les carrés de 16x16 des échantillons de luminance, on recherche des carrés semblables dans l'image suivante. Les différences dans la localisation de ces carrés sont en effet des vecteurs de mouvement. En profitant de la compensation de mouvement ou sans elle, en fonction du codeur, une image prédite est générée et elle est comparée à l'image réelle. La différence, codée comme en cas de codage à l'intérieur de l'image, est transmise au récepteur.
Fig. 2. Règle de prédication du mouvement dane le codage entre les images
A Bloc de 16x16 pixels dans l'image précédente B - Bloc le plus similaire de 16x16 pixels dans une image réelle
Net:
0.00
EUR
Brut:
0.00
EUR
Poids:
0.00
kg
Cette page utilise les fichiers cookie. Vous trouverez plus d’informations concernant les fichiers cookie que nous utilisons, leur emploi et les moyens de changer les paramètres d’acceptation des cookies en cliquant
link
 Français
Français Български
Български Český
Český Dansk
Dansk Deutsch
Deutsch Eesti
Eesti Ελληνικά
Ελληνικά English
English Español
Español Italiano
Italiano Latviešu
Latviešu  Lietuvių
Lietuvių  Magyar
Magyar Nederlands
Nederlands Polski
Polski Português
Português Pусский
Pусский Română
Română Slovenski
Slovenski Slovenský
Slovenský Suomi
Suomi Svenska
Svenska EUR
EUR AUD
AUD CAD
CAD CHF
CHF CZK
CZK DKK
DKK GBP
GBP HUF
HUF NOK
NOK PLN
PLN SEK
SEK USD
USD
 Home
Home Contact
Contact
 Nouveaux produits
Nouveaux produits