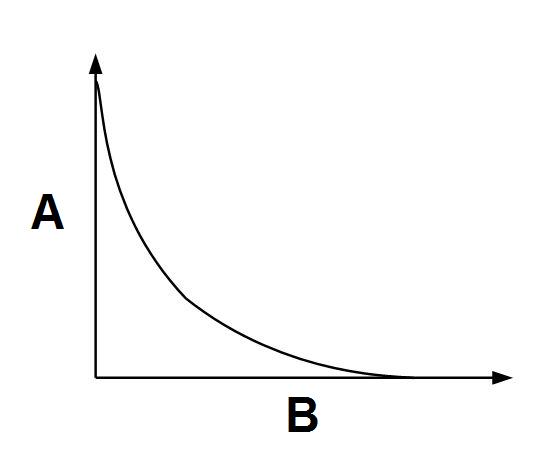
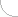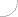Los datos originales que representan imágenes y secuencias visuales grabadas en el formato RGB contienen informaciones redundantes e insignificantes. Las informaciones redundantes se pueden restaurar a partir de otros datos relativos a la misma imagen. En cambio, las informaciones insignificantes son aquellas cuya cancelación no implica un deterioro notable de la calidad de la imagen. La estructura de los algoritmos de compresión permite la evaluación automática de las informaciones consideradas insignificantes que implican distorsiones que casi no son visibles para un observador. El nivel de compresión alcanzado en gran parte depende del contenido de la imagen y también de una pérdida permisible de la calidad de imagen. El siguiente gráfico (fig. 1) presenta una relación teórica entre el flujo de datos y la distorsión.
Fig. 1. Distorsión de la imagen en función del tamaño del flujo de datos
A - Flujo de datos B - Distorsión
La compresión se divide en compresión intraframe e interframe. En el primer caso, se codifica toda la imagen, independientemente de otros fotogramas de la secuencia. En el segundo caso, la codificación depende de los fotogramas anteriores y siguientes.
Representación de colores
Normalmente, se comprimen las imágenes en color. En monitores, las imágenes se obtienen mezclando los tres colores primarios: rojo, verde y azul (RGB). Cada píxel está representado por la suma de estos tres componentes. Por desgracia, los datos así guardados tienen un gran volumen. Debido a la naturaleza del ojo humano, es mejor guardar los datos en forma de luminancia Y y dos crominancias diferenciales Cr y Cb, donde:
La ventaja es que el ojo humano es más sensible a la variación de la luminosidad de los puntos representados por la luminancia y es menos sensible a la variación del color representada por la crominancia. Por lo tanto, la señal de crominancia puede ser diezmada. En los sistemas de televisión analógicos, tales como PAL, SECAM o NTSC, se ha aprovechado esta propiedad y aproximadamente la mitad de la banda se ha utilizado para la transmisión de la señal de crominancia, sin perder la calidad de imagen de manera notable.
Compresión intraframe
La esencia de las contemporáneas técnicas de compresión intraframe está en el hecho de que el espectro de la señal visual está centrado fuertemente en torno a las frecuencias más bajas. Entonces hay que calcular el espectro de la señal y guardar una pequeña cantidad de coeficientes de relevancia (en su mayoría con las frecuencias más bajas), los otros (en su mayoría correspondientes a frecuencias más altas) se pueden grabar en una cantidad muy pequeña de bits.
En la práctica, las imágenes se dividen en bloques de 8x8 puntos y se calcula la transformada de coseno (transformada de Fourier modificada). La secuencia numérica resultante se divide por una tabla de cuantificación especial. Como resultado de esta operación se obtienen muchos ceros repetidos. La representación resultante se registra en los siguientes pares: número de ceros, valor del coeficiente diferente de cero. Los resultados obtenidos se registran mediante códigos de bits de longitud variable. Esto significa que a los pares más comunes se les asignan los códigos con menos bits, mientras que a los pares que se producen con menor frecuencia se les asignan los códigos con más bits.
Compresión interframe
La codificación interframe consiste en aprovechar el hecho de que en una secuencia de vídeo el fotograma anterior y el siguiente son en general muy similares. Así que simplemente hay que enviar el error de predicción, es decir, la diferencia entre una imagen y su predicción. En el caso más simple, se espera que la próxima imagen es idéntica a la anterior.
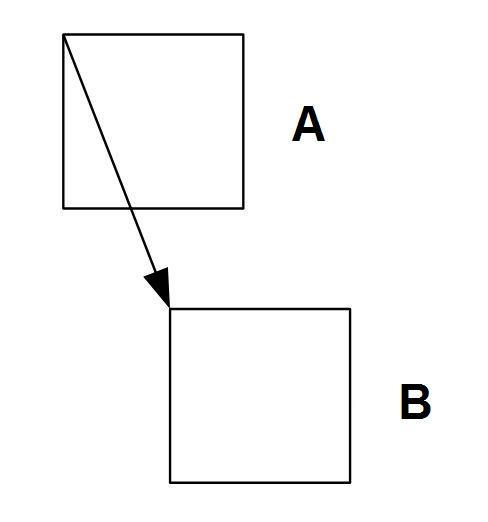
En codificadores más avanzados, la compensación de movimiento se utiliza para la predicción. Para los cuadrados de 16x16 muestras de luminancia se buscan los cuadrados más parecidos a ellos en la siguiente imagen. Las diferencias de localización de estos cuadrados son los vectores de movimiento. Usando la compensación de movimiento o sin ella, en función del codificador, se genera la imagen prevista y se compara con la imagen real. La diferencia, codificada como en la codificación intraframe, se envía al receptor.
Fig. 2. Principio de predicción del movimiento en la codificación interframe
A - Bloque de 16x16 píxeles en la imagen anterior B - Bloque más parecido de 16x16 píxeles en la imagen actual
Neto:
0.00
EUR
Bruto:
0.00
EUR
Peso:
0.00
kg
Este sitio utiliza cookies. Para obtener más información acerca de los archivos cookie utilizados por nosotros, su uso y la forma de modificar la aceptación de cookies, haga clic en
link
 Español
Español Български
Български Český
Český Dansk
Dansk Deutsch
Deutsch Eesti
Eesti Ελληνικά
Ελληνικά English
English Français
Français Italiano
Italiano Latviešu
Latviešu  Lietuvių
Lietuvių  Magyar
Magyar Nederlands
Nederlands Polski
Polski Português
Português Pусский
Pусский Română
Română Slovenski
Slovenski Slovenský
Slovenský Suomi
Suomi Svenska
Svenska EUR
EUR AUD
AUD CAD
CAD CHF
CHF CZK
CZK DKK
DKK GBP
GBP HUF
HUF NOK
NOK PLN
PLN SEK
SEK USD
USD
 Inicio
Inicio Contacto
Contacto
 Nuevos productos
Nuevos productos