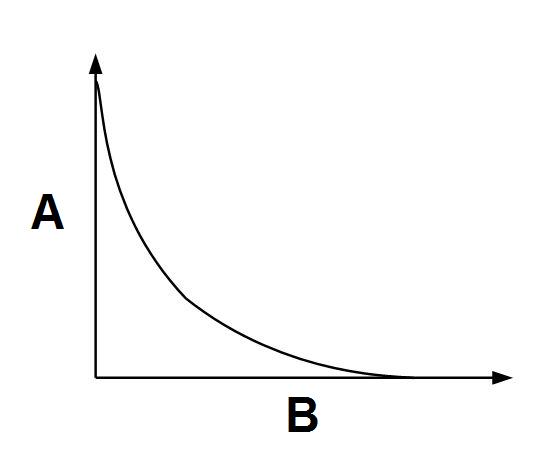
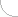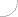The original data representing the images and video sequences stored in the RGB format include redundant and non-essential information. The redundant information can be restored based on the remaining image data, while non-essential information can be removed without deterioration of the image quality. A compression algorithm automatically evaluates which non-essential information, when removed will result in least distortion. A compression ratio depends on the content and acceptable loss of image quality. The graph below (Fig. 1) shows a theoretical relationship between the data stream and the distortions.
Fig. 1. Image distortion as the function of data stream size.
A - Data stream B - Distortion
The compression can be defined as intraframe or interframe. The intraframe compression involves coding of the entire image, irrespective of the remaining frames. The interframe compression depends on the previous and subsequent frames.
Colour rendering
The compression usually applies to colour images. Any displayed image is a combination of three primary colours: red, green and blue. Each pixel is represented by a sum of those three components. However, data stored this way may take a lot of storage space. Due to the nature of the human eye, it is more convenient to store the images as luminance Y and chrominances Cr and Cb, where:
The human eye is more sensitive to changes in the brightness of points represented by the luminance and to a lesser degree to changes in colour represented by the chrominance. Thus, the chrominance signal can be decimated. In analogue television system including PAL, SECAM or NTSC, this property has been utilized to transmit the chrominance signal using half the bandwidth without any deterioration of the image quality.
Intraframe compression
Modern intraframe compression techniques are based on the fact that the video signal spectrum is focused around the lowest frequency. Thus, a signal spectrum can be calculated and a small number of significant coefficients (usually at the lowest frequencies) can be stored, while other (usually corresponding to the higher frequencies) can be stored using less bytes.
In practice, the image is divided into 8x8 point blocks and a cosine transform (modified Fourier transform) is calculated. The calculated string is divided by a special quantization table giving a string of repeating zero digits. The representation is stored as a pair including the number of zero digits and a non-zero coefficient value. The results are stored using codes with variable bit length. It means that the frequently occurring pairs are assigned shorter codes, and rarely occurring pairs are assigned longer codes.
Interframe compression
The interframe compression is based on the fact that the previous and subsequent frame in the video sequence are often similar. It is usually enough to transmit a prediction error, i.e. the difference between the image and its prediction. In the most simple case, it can be predicted that the subsequent image is identical to the previous one.
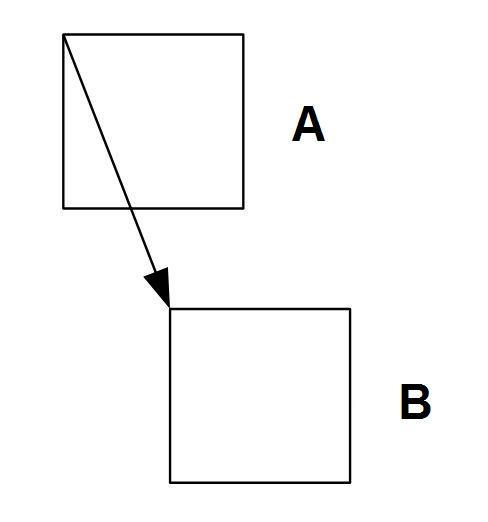
In more advanced encoders, a motion compensation is used to predict the subsequent image. The most similar squares in the subsequent image are identified for 16x16 luminance samples. A difference in the position of those blocks is referred to as a motion vector. With or without the motion compensation, depending on the encoder used, a predicted image is generated and compared with the actual image. The difference, encoded using similar techniques as used in the intraframe encoding is send to the receiver.
Fig. 2. Motion prediction rules in the interframe compression
A - 16x16 block in the previous image B - the most similar 16x16 block in the actual image
Net:
0.00
EUR
Gross:
0.00
EUR
Weight:
0.00
kg
This site uses cookies. More information about using by us cookie files, their usage and how to modify the acceptance of cookie files, can be found by pressing
link
 English
English Български
Български Český
Český Dansk
Dansk Deutsch
Deutsch Eesti
Eesti Ελληνικά
Ελληνικά Español
Español Français
Français Italiano
Italiano Latviešu
Latviešu  Lietuvių
Lietuvių  Magyar
Magyar Nederlands
Nederlands Polski
Polski Português
Português Pусский
Pусский Română
Română Slovenski
Slovenski Slovenský
Slovenský Suomi
Suomi Svenska
Svenska EUR
EUR AUD
AUD CAD
CAD CHF
CHF CZK
CZK DKK
DKK GBP
GBP HUF
HUF NOK
NOK PLN
PLN SEK
SEK USD
USD
 Home
Home Contact
Contact
 New products
New products